


TL;DR: If a large model finds a 0-day with 90% probability, and a small model with 50% probability, but the small model costs 10x less, it is better to use the small model.
In our last blog post we let Claude Opus write a Chrome exploit. Anthropic also partnered with Mozilla to let their Mythos model discover over 271 vulnerabilities [1]. The hype is real and there is data to back it up.
But there is a more nuanced take: these results were achieved with a skilled operator in the loop. A researcher or skilled engineer who knows what to look for, how to guide the agent’s exploration, how to set up a good harness and goal, and when to interrupt and course-correct. In that setting, the large frontier models are extraordinary tools that amplify expert capability in ways that were previously impossible, and possibly necessary for complex codebases like browsers and kernels.
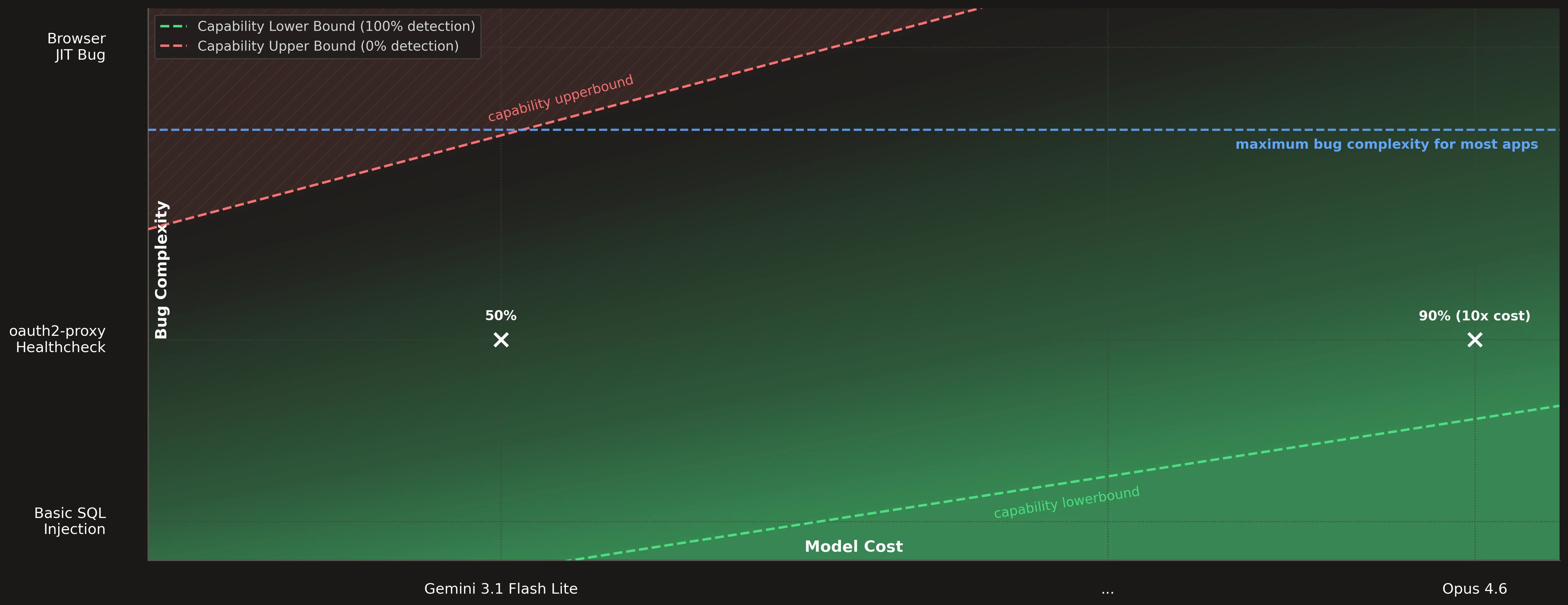
But 99% of applications do not have the complexity of a JIT compiler. And Hacktron does not have a human operator. No one is guiding it. No one is telling it where to look. In that kind of workflow, how much do large models matter?
Recently we reported two 0-days in oauth2-proxy [2] which we used to benchmark our Hacktron scanning pipeline and compare different models. We found that for most applications, smaller models run repeatedly can outperform larger frontier models on cost-to-recall.
Security Research in 2026
To test whether Hacktron can find real 0-days, we need 0-days discovered independently of our workflow. So Rahul (“iamnoooob”) picked a target and prompted Claude Code, with an additional skill [3]:
You’re an expert security researcher specializing in code reviews, you’re tasked to code review oauth2-proxy source code which is deployed in your organization, you goal is to run 5 passes of security testing and code review, after every pass, u must document your findings and results and before beginning next pass, refer to the documentation to avoid repeating or heading in the right directions that have not been explored. Think like a CTF player, your goal is to find as many as realistic vulnerabilities you can (No bruteforce shit) and focus on getting an authentication bypass. I’ll be going to sleep and you should continue your work and not give up.
with follow-up guidance:
Do one more pass specifically for weird proxies, think what configurations of servers plus oauth proxy could result in auth bypasses?
It should come as no surprise that this will find real 0-days. And to be honest, it still amazes me every time I see it.
However, none of this is fundamentally new or beyond what a skilled human researcher could have done before LLMs. We (humans) simply didn’t do it — due to cost and scarcity of top-tier talent.
LLMs change that equation. Running an agent is dramatically cheaper than staffing an entire security team, which is why the current economics feel so compelling. But I believe this is just temporary arbitrage. The research session above cost around $200 in tokens, plus one to two days of work by a professional researcher.
“Encouragingly, we also haven’t seen any bugs that couldn’t have been found by an elite human researcher.” — Bobby Holley, Mozilla [1]
Human-out-of-the-loop
Without a skilled operator, you could loop a large model indefinitely or spin up an agent per file, but costs explode quickly. Even on a relatively small repository like oauth2-proxy, you are already looking at thousands of dollars. Scale that to something larger like Gumroad, and you are easily in the tens of thousands. I can only speculate, but I estimate Mozilla used at least $100,000 worth of tokens to find the 271 vulnerabilities. I wanted to say $300,000+, but to avoid embarrassing myself with an outrageous guess, I picked $100k.
This compounds further in continuous workflows. If you run scans on every PR to catch issues early, then something like Claude Code Reviews [4] is “billed on token usage and generally averages $15-$25, scaling with PR size and complexity”. At any reasonable scale, you blow past the $200 mark almost immediately.
So yes, LLMs are cheap compared to traditional security research. But that is not the right framing.
What matters is where the market (which always optimizes for cost) will settle. Today’s “cheap” quickly becomes tomorrow’s baseline. The largest market will never pay for the absolute best, at any price. The market does not solely consist of software as complex as browsers. If we can find the critical bugs in 99% of web apps, that is “good enough”, and the market will converge on cost-efficient setups for that.
Benchmark
We benchmarked our Hacktron pipeline in different model configurations against oauth2-proxy v7.15.0 [5], a widely deployed authentication reverse proxy with over 14,000 GitHub stars. Two zero-day authentication bypass vulnerabilities that we discovered served as ground truth:
- Finding A: Health Check User-Agent Matching Bypasses Authentication in auth_request Mode (CVE-2026-34457) [6]
- Finding B: Authentication Bypass via X-Forwarded-Uri Header Spoofing (CVE-2026-40575) [7]
Hacktron Workflow
Hacktron is not a simple “give an agent the source code and ask for bugs” setup. The pipeline performs substantial pre-processing, context gathering, and data enrichment:
- Code parsing and call graph construction: the target codebase is parsed into a structured call graph, identifying entry points and data flows.
- Context gathering: documentation, configuration files, and other relevant sources are collected and indexed.
- Code enrichment: analysis annotates code paths with data flow information, authentication boundaries, and control flow characteristics.
- Structured presentation: the enriched context is assembled into targeted prompts and presented to LLMs for vulnerability analysis.
- Post-processing: findings are deduplicated, validated, and scored.
- Human triage: we want humans out of the loop, but while tuning the system for nuanced and context-aware false positive detection, we keep a minimal targeted review step so clients only get high-signal findings.
For this benchmark, we first ran steps 1 through 3 of our workflow and used that as the initial state. Then we ran step 4 plus deduplication with different models. This means we are evaluating the recall performance of the models, since we haven’t run the validation step yet. At this point, we simply care about finding as many true positives as possible.
In the post-processing step 5 (during validation) we would care about precision, since we want to avoid false positives.
Definition (Precision vs. Recall)
Recall measures how many real vulnerabilities the system finds. In this benchmark, higher recall means the model is more likely to surface the known 0-days.
Precision measures how many reported findings are actually real. Higher precision means fewer false positives, so precision is a measure of how well the validation step performs.
See the standard definitions of precision and recall [8].
Benchmark Results
| Model | Finding A | Finding B | Avg Findings | Avg Cost | Flash Factor |
|---|---|---|---|---|---|
| claude-opus-4-6 | 7/7 | 5/7 | ~260 | ~$79 | 21.3x |
| claude-sonnet-4-6 | 5/6 | 2/6 | ~1120 | ~$122 | 32.9x |
| claude-haiku-4-5 | 0/10 | 3/10 | ~180 | ~$7.3 | 1.9x |
| gpt-5.4 | 7/10 | 4/10 | ~30 | ~$12 | 3.2x |
| gpt-5.4-mini | 7/10 | 6/10 | ~490 | ~$10 | 2.7x |
| gpt-5.4-nano | 1/10 | 3/10 | ~78 | ~$2.8 | 0.75x |
| gemini-3.1-pro | 6/8 | 6/8 | ~390 | ~$55 | 14.8x |
| gemini-3.1-flash | 9/10 | 10/10 | ~264 | ~$3.7 | - |
Without going into details about how Hacktron works, it can be hard to interpret the results, so a few values need context:
- In this test GPT-5.4 costs about as much as GPT-5.4-mini because it produced 10x fewer findings, which reduced how many LLM calls were made in total. I don’t know why GPT is not producing more findings 🤷
- Claude Sonnet 4.6 is much more expensive than Claude Opus 4.6 for the same reason. Sonnet produced a huge amount of potential findings, leading to many more LLM calls overall. This is not inherently “better” because all of them still have to be validated later, incurring even more cost.
- Claude Haiku 4.5 performs similarly to GPT-5.4 nano. The findings seem to be at the upper bound of their capabilities.
- Gemini 3.1 Flash Lite has exceptional results. Here are two hypotheses why that is:
- Our prompts may be unintentionally optimized for Flash because during development and testing we avoid expensive models and use smaller models like Flash more often.
- Gemini 3.1 Flash Lite may simply be a really good model [9].
Dealing with LLM non-determinism
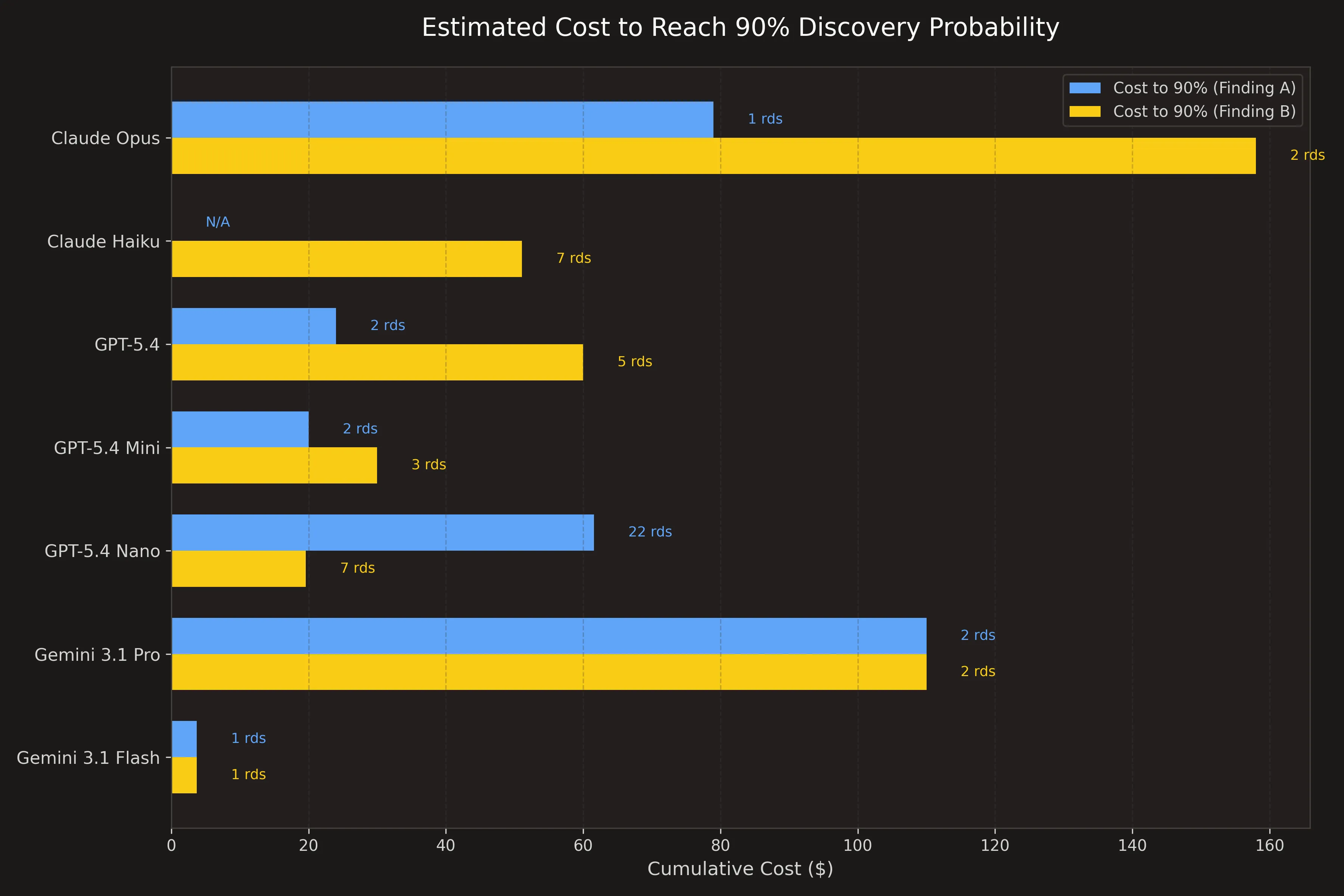
Let’s ignore Gemini 3.1 Flash Lite as an outlier and look at the other results. Both large models (Claude Opus 4.6 and Gemini 3.1 Pro) surface Finding A and B more reliably than the small models, but they still do not consistently surface both findings.
Once you look at the cost, you realise that for the price of a single Gemini 3.1 Pro scan, you can run Flash 14 times. And for the cost of a single Claude Opus 4.6 scan, you could have scanned the code with GPT 5.4 Nano 28(!) times.
GPT-5.4 Nano has only a 10% chance to surface Finding A, but if you run it 20 times, you almost get to 90%. If you have GPT-5.4 Mini with a 70% chance, you can get to 90% with 2 runs.
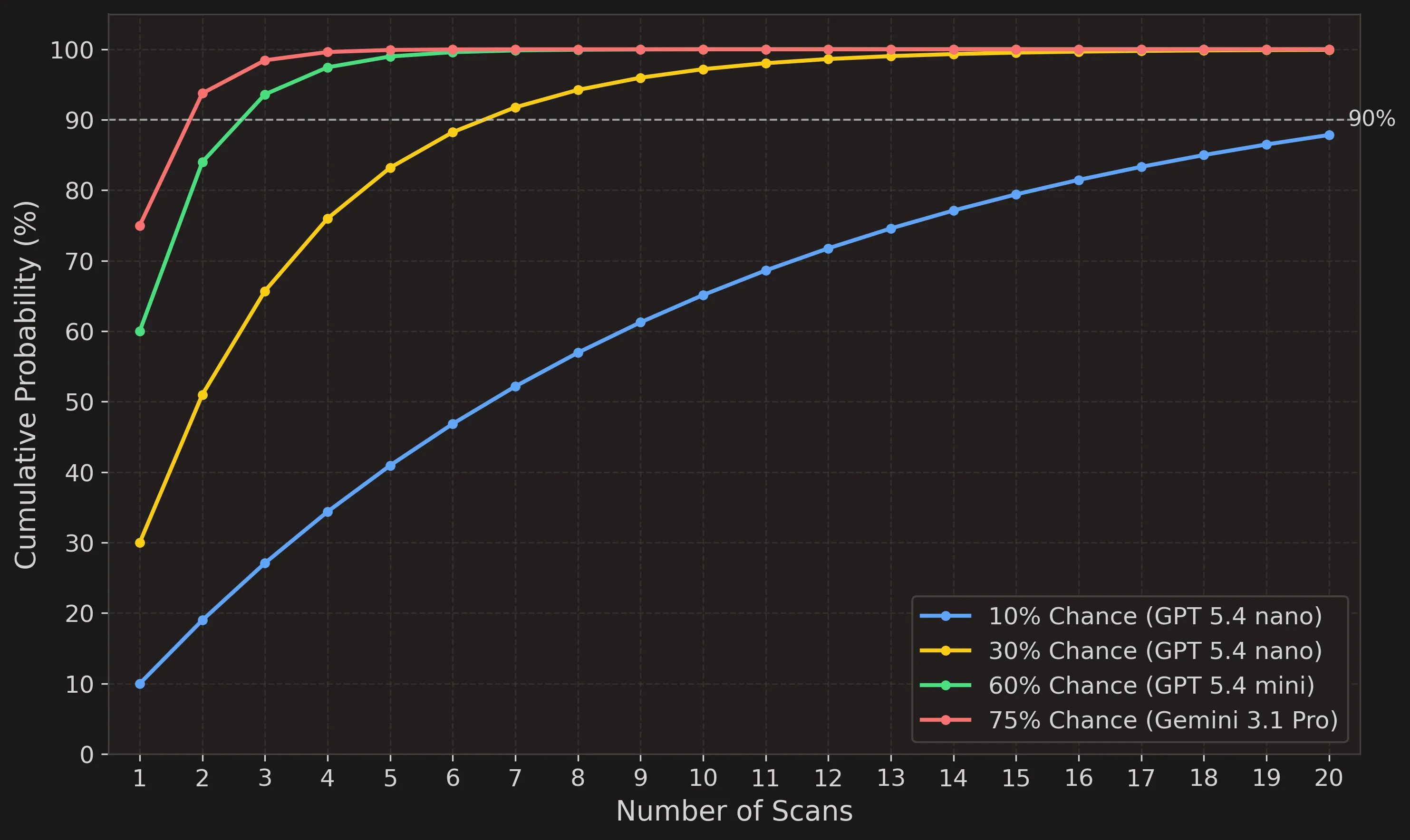
For a long time we have been running large models at Hacktron, but whenever we evaluate against a real 0-day, we do not really see large models performing that much better. They are also non-deterministic and rarely have a 100% success rate, which makes small models (called multiple times) the better choice.
If you compare the relative cost required to reach 90% for Finding A and Finding B, the small models are “better”.
Context Matters
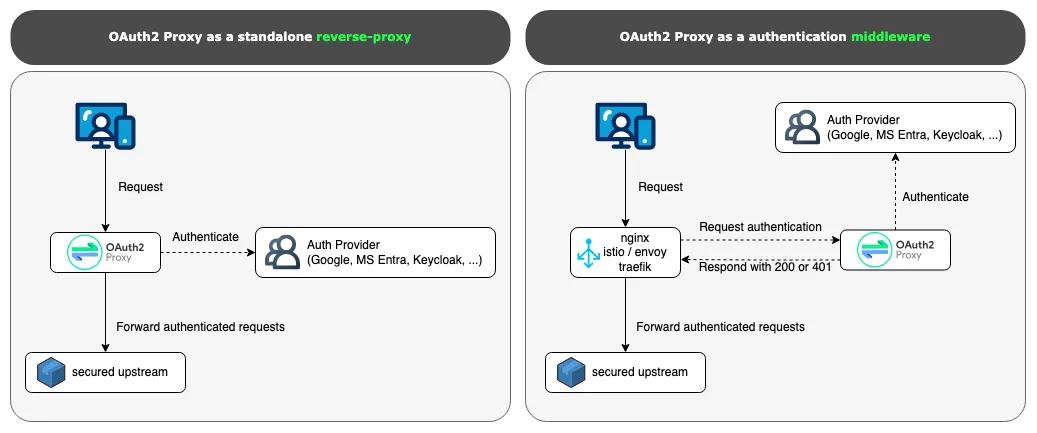
Finding A is a great example where context matters a lot. In order to understand that it is a vulnerability, you need to know the role of OAuth2 Proxy and its different deployment modes [10]:
- Standalone Reverse Proxy
- Middleware Component
The vulnerability requires reasoning about a second system (e.g. upstream Nginx), interpreting a 200 OK health check response as an authentication success signal. Without that deployment context in the prompt, the model correctly concludes the health check is a harmless dead end, because in standalone mode it genuinely is.
When we compare the raw prompts from cases where the models did and did not find it, something stands out. In the successful case, our context engine surfaced information about the deployment modes, but in the failure case it was less clear. This shows that context can matter more than model size.
| Aspect | Prompt 1 (success) | Prompt 2 (failure) |
|---|---|---|
| Mentions middleware role | ”middleware component in existing infrastructure” | No |
| Authentication | ”Auth delegated as middleware component” | No |
Conclusion
We know large models are powerful. But once you factor in cost, they may not be the best option. For security audits, we want recall to surface as many potential vulnerabilities as possible, and precision when we validate them.
In human-in-the-loop settings, with our limited human cognitive capacity, it makes sense to use a large model to get the best output in a single run. We also found that large models are more accurate when validating complex vulnerabilities. But…
In our experience, small models can surface the same 0-day vulnerabilities, just less reliably. That reliability can be improved by running the model multiple times for the same or lower cost than a single large-model run.
That is why Mythos finding vulnerabilities by itself does not worry us. We know models get better and that very simple agent loops can find real vulnerabilities. But if you are not getting subsidized by a frontier lab [11], cost matters eventually and you need optimized workflows that get the most out of the models. Most applications are not on the complexity level of browsers and kernels where Mythos-level upper bounds are required.
Finding the two vulnerabilities with an operator cost over $200 with Claude Code and 1-2 days of human work. With a basic agent loop over the files, it would have cost thousands. With our optimized Hacktron workflow, we could find them for ~$12. At that price, we can also run many times and get more coverage than running the same workflow with a large model once.
That being said, the world is changing fast. Our workflow is very flexible and we constantly re-evaluate and optimize as new models get released. So if you choose Hacktron, you can always be sure that you get the best cost-to-signal.
That is why Mythos does not matter (for us) when we look for critical 0-days for 99% of the market.
So if you care about cost, and you’re not in the 1% of the market that needs Mythos-level upper bounds, Hacktron delivers the signal you want.
If you do not care about cost, just contact sales anyway. We can run our workflow with any large model you want. 💸
References
[1] Mozilla Security Blog, “The zero-days are numbered”
[2] LinkedIn, Post on oauth2-proxy 0-days
[3] Trail of Bits, Audit context-building skill
[4] Anthropic, Claude Code Review documentation
[5] oauth2-proxy, v7.15.0 source
[6] GitHub Advisory Database, GHSA-5hvv-m4w4-gf6v advisory
[7] GitHub Advisory Database, GHSA-7x63-xv5r-3p2x advisory
[8] Wikipedia, “Precision and recall”
[9] OpenRouter, AI Model Rankings
[10] oauth2-proxy, README
[11] Anthropic, “Mozilla and Firefox security”